
V knjižničnih katalogih je ključnega pomena, da so podatki kakovostni in dosledno strukturirani v skladu s standardi, ki jih določa knjižnična stroka. Le tako je mogoče zagotoviti natančno in učinkovito identifikacijo in dostopnost informacijskih virov, kar bistveno pripomore k zadovoljstvu uporabnikov in učinkovitosti knjižničnega sistema kot celote.

Spremljanje kakovosti bibliografskih in pripadajočih normativnih zapisov v letu 2023
Spremljanje kakovosti zapisov dnevne produkcije se izvaja od junija 2015 z namenom sprotnega ugotavljanja značilnosti in težav pri novejših zapisih. Z metodo vzorčenja 10 % bibliografskih zapisov s pripadajočimi normativnimi zapisi, kreiranimi na določen dan, smo v letu 2023 izvedli 36 zajemov in vzorčili 2.025 zapisov. Te je kreiralo 328 različnih katalogizatorjev iz 174 različnih ustanov. Skoraj polovica pregledanih zapisov je bila za monografije (47 %), 43 % za članke in druge sestavne dele in 9 % za izvedena dela. Glede na vrsto zapisa so prevladovali tiskani (64 %) in elektronski viri (14 %), sledili so zapisi za dogodke (9 %) in muzikalije (2 %) in druge vrste zapisov.
V pregledu brez predloge (razen virov, dostopnih prek spleta) je bilo ugotovljeno, da je bilo 38 % zapisov ustreznih, 44 % jih je imelo manjšo pomanjkljivost, 4 % jih ni dobilo preglednega komentarja, pri 15 % zapisov pa smo zasledili vsaj eno večjo pomanjkljivost, kot je to določeno s Kriteriji za ocenjevanje bibliografskih in normativnih zapisov v COBISS.SI (2009), ali pa vključujejo napake, povezane s formatom. Kreatorje/redaktorje zapisov, ki imajo najmanj eno večjo pomanjkljivost, smo obvestili prek e-pošte. V letu 2023 smo e-sporočilo poslali 158 različnim katalogizatorjem iz 98 različnih ustanov. V primerjavi s podatki iz prejšnjih let je opaziti, da je delež zapisov z večjo pomanjkljivostjo zapisov manjši.
Tudi v letu 2023 smo izvedli analizo priporočil v skladu z definicijo kakovosti podatka v bibliografskem in normativnem zapisu, ki določa dimenzije kakovosti. Po tej definiciji je podatek v bibliografskih in normativnih zapisih kakovosten, kadar je naveden v edinstvenem zapisu (EDIN), semantično točen (SEMTOČ), točno prepisan (TOČPRE), strukturalno popoln (STRUPOP), vsebinsko popoln (VSEBPOP), strukturalno skladen (STRUSKLAD), vsebinsko skladen (VSEBSKLAD), oblikovno dosleden (OBLIDOS), predviden oziroma ni odvečen (ODVEČ) in aktualen (AKT) in (lahko) tudi dodatno informativen (DODV).
V 1.207 bibliografskih zapisih z vsaj eno pomanjkljivostjo smo analizirali 1.463 slabih podatkov na nivoju podatkovnega elementa ali nivoju zapisa, kot to določa posamezna dimenzija. Najbolj pogosto so manjkali priporočljivi podatki (DODV; 30 %) in drugi podatki (STRUPOP; 11 %). Beležili smo tudi težave s točnostjo (SEMTOČ; 32 %) in oblikovanjem (OBLIDOS; 9 %) podatkov. Sledile so napake, povezane z odvečnimi podatki (ODVEČ; 5 %), vpisom podatkov v napačno (pod)polje ipd. (STRUSKLAD; 6 %), pomanjkljivostjo podatkov (VSEBPOP; 2 %) ali pa se podatki niso ujemali (VSEBSKLAD; 3 %). Zatipkanih podatkov (TOČPRE) je bilo 2 odstotka; podvojenih zapisov ni bilo (EDIN). V primerjavi s prejšnjimi leti opazimo, da je delež napačnih podatkov (SEMTOČ) še vedno visok, dve tretjini priporočil v okviru te dimenzije sta se nanašali na napačne indikatorje v poljih 701 in 702, po sklepu o ukinitvi dodatnih vpisov, objavljenem leta 2021. Opaziti je tudi manjši delež zatipkanih podatkov (TOČPRE) (slika 1).
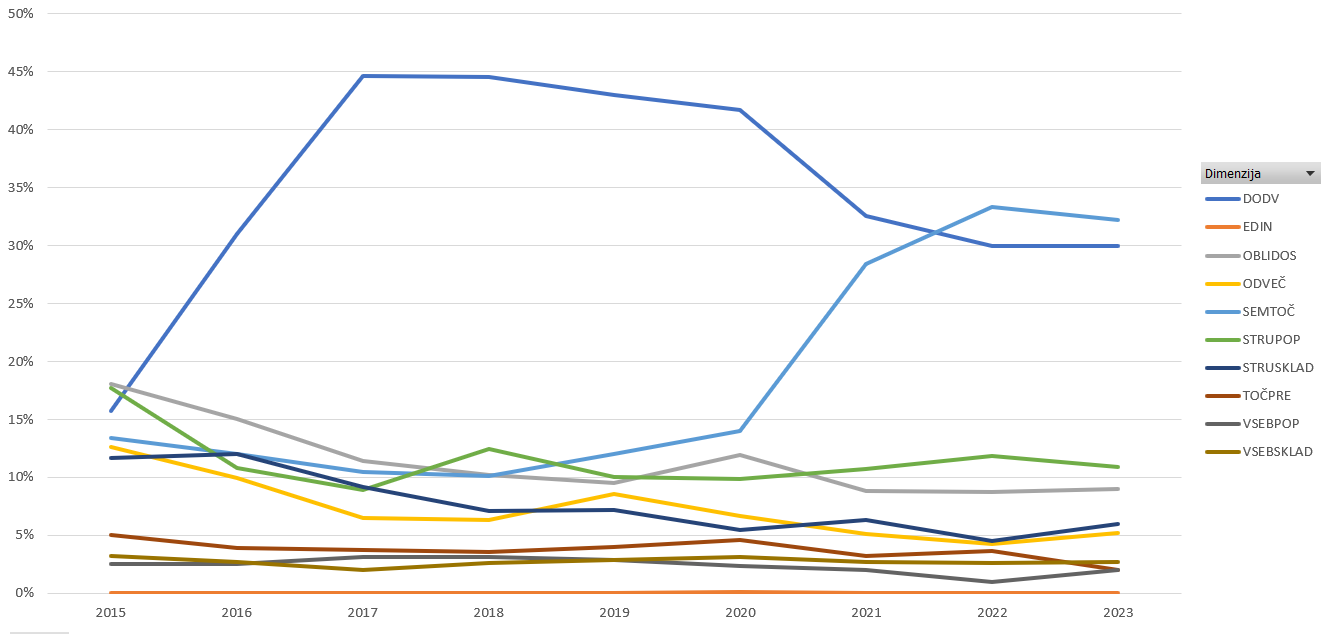
Pri zabeleženih 1.254 opombah pri pripadajočih normativnih zapisih smo najpogosteje predlagali vnos priporočljivih podatkov (DODV; 7 %) in manjkajoče obvezne podatke (STRUPOP; 3 %). Pri 1.106 pripadajočih normativnih zapisih smo katalogizatorjem s pooblastili CAT_NEWPN priporočali tudi ažuriranje zapisa (AKT; 88 % od vseh priporočil). V primerjavi s prejšnjimi leti opažamo, da smo pri normativnih zapisih opozarjali predvsem na možnost ažuriranja zapisa v celoti (AKT). Višji delež le-tega je tudi posledica beleženja pomanjkljivosti, saj smo z letom 2022 v priporočilu začeli beležiti tudi dejanske CONOR-ID-je.
Z enomesečnim zamikom po zadnjem zajemu v letu vzorčimo 10 % pregledanih zapisov, za katere smo katalogizatorjem poslali e-sporočila, in sicer z namenom, da preverimo, ali in kako so bile pomanjkljivosti odpravljene. S tem postopkom preverimo tudi ustreznost poslanih priporočil. V letu 2023 smo naključno izbrali 31 zapisov, ki jih je kreiralo 29 različnih katalogizatorjev iz 24 različnih ustanov. Zadovoljni smo, da se je 82 % katalogizatorjev na priporočila odzvalo, večina popravkov v izbranih zapisih je bila ustreznih.
Strukturiranost podatkov pri prevedenih delih
Skladna struktura omogoča knjižničarjem in uporabnikom, da hitro in enostavno identificirajo, ali določen vir predstavlja prevod ali izvirno delo, ter dostopajo do informacij o avtorju izvirnika, prevajalcu, letu prevoda in do drugih pomembnih podatkov. Pravilno strukturirani podatki omogočajo natančno razlikovanje med temi različicami in uporabnikom olajšajo iskanje prevodov v njihovem izbranem jeziku. Uporabniki kataloga COBISS+ imajo že od leta 2017 na voljo informacije o »vseh izdajah in prevodih« posameznega dela, vendar ima programsko povezovanje določene omejitve[1], nekaterim zapisom pa primanjkujejo bistveni podatki ali pa so ti napačni.

V letu 2023 smo izvedli aktivnost, s katero smo preverili semantično točnost indikatorja za prevode v polju 101 – Jezik enote in hkrati skladnost z drugimi podatkovni elementi, kot je podatek o prevodu v polju 300 – Splošna opomba in podatek o izvirnem naslovu v polju 500 – Enotni naslov.
Z iskalno zahtevo (001c=m not (dt=c or rs=d or rs=p or cr=*old or cr=ctk springer* or cr=uplsi* or cr=knt izum_)) and 101ind1=0 and (300a=*prev* or 300a=*izv. stv* or 500a=* or 7024=730) smo z dne 13. 9. 2023 zajeli 38.906 bibliografskih zapisov. Potem smo z ročno preverbo izločili zapise za nekatere vrste gradiva, ki imajo kompleksnejše strukture opisa, nato pa še zapise, ki nimajo redaktorjev oz. niso bili kreirani v slovenskih knjižnicah, ipd.
Po ročnem pregledu je v vzorcu ostalo 7.928 bibliografskih zapisov, po e-pošti smo zaprosili 190 ustanov, da po potrebi uredijo podatke. Pri preverbi je bilo treba:
-
- v polju 101 – Jezik enote določiti ustrezni indikator glede na to, ali je enota prevod, nato uskladiti podatke v podpoljih 101a – Jezik besedila, 101b – Jezik posrednega besedila in 101c – Jezik izvirnika (gl. COMARC/B, polje 101; Katalogizacija monografskih publikacij – pogosta vprašanja in novosti (2020));
- v poljih 300 – Splošna opomba preveriti, ali je podatek naveden, in uporabiti ustrezno uvodno frazo; kadar je npr. v publikaciji naveden izvirni naslov, je opomba o prevodu dela obvezna, uporabljamo pa uvodno frazo »Prevod dela:« (gl. Prekat, pogl. 7.1.1; Katalogizacija monografskih publikacij – pogosta vprašanja in novosti (2020));
- v polju 500 – Enotni naslov, ki ga uporabljamo za povezovanje prevodov z izvirnimi deli, navesti izvirni naslov, glede na strukturo naslova, v podpolju 500m – Jezik podati jezik publikacije, tj. jezik prevoda (npr. 500aElephants can remember mslovenski jezik) (gl. COMARC/B, polje 500; Katalogizacija monografskih publikacij – pogosta vprašanja in novosti (2020));
- v poljih 70X povezati odgovornosti z normativno bazo CONOR prek podpolja 70X3 in dodati manjkajoče kode avtorstva v podpolju 70X4 (gl. COMARC/B, blok 7XX).
- Priporočali smo tudi vnos podatkov v podpolja 100e – Koda za namembnost, 105b – Kode za vrsto vsebine ali 105f – Koda za literarno vrsto (gl. COMARC/B, polji 100, 105).
Za vsako aktivnost sta potrebna znanje in čas, zato se zahvaljujemo katalogizatorjem, da se zavedajo pomena podatkov in se tudi pozitivno odzivajo na pobude, ki izboljšujejo kakovost in navsezadnje tudi uporabniško izkušnjo v knjižnicah. To je dobra spodbuda za prihodnje projekte, ki bodo prispevali k večji dostopnosti in učinkovitosti knjižničnih storitev za vse.
Prispevek pripravila: mag. Branka Badovinac
Viri:
-
- Krajnc Vobovnik, A., & Mazić, G. (2017). Združevanje bibliografskih zapisov v COBISS+: začetek novih katalogov v sistemih COBISS. Knjižnica, 61(1–2), 87–100. https://doi.org/10.55741/knj.61.1-2.13850 ↑