
V sodobnih knjižničnih sistemih je normativna kontrola nepogrešljiva. V spletnih knjižničnih katalogih se za iskanje po vsebini kot glavni pripomoček uporabljajo kontrolirani slovarji in klasifikacijske sheme. Z razvojem umetne inteligence so algoritmi za iskanje po besedilnih datotekah dobili nepredvidene razsežnosti. Zdi se, da je kompleksnost jezika postala manj omejujoča.

Latentno semantično indeksiranje (LSI) je spodbudilo razvoj orodij za analizo besedila, ki strojno prepoznavajo kontekst in na tej osnovi iščejo povezane ključne besede.
LSI (Latent Semantic Indexing/latentno semantično indeksiranje) je tehnika procesiranja naravnega jezika, ki analizira kontekst, v katerega so umeščene besede v besedilu, da bi ugotovila pomen in teme besedila. Na podlagi odnosov med besedami in frazami znotraj nekega dokumenta in s primerjanjem podobnih besedil ne ugotavlja le dobesednega pomena besedila, ampak poskuša identificirati pomen za besedami.
S kontroliranimi slovarji oz. geslovniki že desetletja delamo prav to – pomagamo širiti kontekst besed, ponujamo sorodne oblike izrazov (sopomenke), razlikujemo isto zveneče besede (homonime) in tkemo povezave med gesli (hierarhične in asociativne). Tega ne opravljamo strojno, ampak s človeškim premislekom. Učinkovitega geslovnika namreč ne moremo generirati avtomatizirano, na primer na podlagi seznamov ključnih besed v podatkovnih datotekah. Tehtno premišljeni geslovniki pa so nujno potrebni za nove, učljive tehnike umetne inteligence.
Avtomatizirano predmetno označevanje je še v povojih in ostaja pri poskusih, katerih rezultati še niso izkazali prave zanesljivosti. Obdelava jezika je namreč zahteven proces, saj je človeški jezik tako kompleksen, da ga računalniki zaradi dvoumnosti besed in drugih ovir ne morejo premočrtno in dobro razbirati. Besede dobijo svoj pomen samo v semantičnem kontekstu besed, med katere so umeščene. Procesiranje naravnega jezika (NLP) zato temelji na informacijski ontologiji, ki z entitetami in atributi sestavlja kompleksno mrežo odnosov. Teh pa ni tako preprosto strojno razrešiti.
NLP (Natural Language Processing/procesiranje naravnega jezika) je področje umetne inteligence, ki združuje lingvistiko, strojno učenje in modele globokega učenja. Raziskuje, kako izuriti računalnik, da lahko ta komunicira s človekom, razume človeški jezik in iz besedila izlušči pomen.
Eden izmed najuspešnejših poskusov je gotovo programsko orodje Annif, ki so ga za avtomatizirano predmetno označevanje razvili v finski nacionalni knjižnici v Helsinkih. Ker je razmeroma preprost in ima odprtokodno licenco, ga lahko uporablja vsakdo. Nastopa globalno, saj je jezikovno neodvisen in podpira kateri koli geslovnik v formatu SKOZ ali TSV. Uporablja algoritme za procesiranje naravnega jezika in različna orodja za strojno učenje (TensorFlow, Omikuji, fastText, Gensim). S preprostim poskusom analize poljubnega besedila na njihovi spletni strani lahko ugotovimo, da so predlagana predmetna gesla zelo splošna, presplošna za učinkovito predmetno označevanje s kontroliranimi slovarji, kjer je dober priklic rezultatov odvisen predvsem od specifičnosti predmetne oznake.
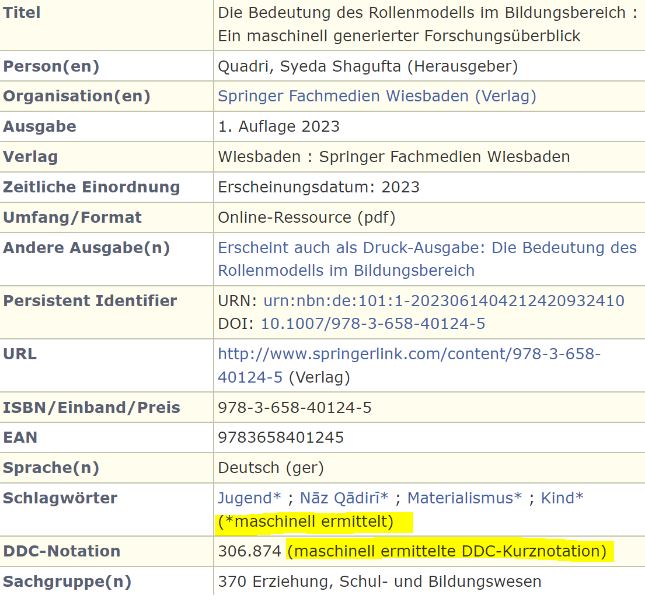
Leta 2022 so v Nemški narodni knjižnici začeli uporabljati »katalogizacijski stroj« (EMa oz. Erschliesungsmachine), novi sistem za avtomatizirano predmetno označevanje. Z njim so začeli generirano dodeljevati kratko klasifikacijsko številko, kasneje pa določati tudi predmetne oznake. Namenjen je digitalnim zbirkam s celotnimi besedili, predvsem člankom v e-revijah in univerzitetnim nalogam. Sistem je zastavljen kot dopolnilo klasični vsebinski katalogizaciji. V jedru sistema je Annif, za predmetno označevanje pa uporablja deskriptorje normativne baze GND (Gemeinsame Normdatei).
Tudi ameriški knjižničarji na Univerzi v New Yorku so se začeli ukvarjati z avtomatiziranim predmetnim označevanjem digitalnih zbirk s tehnologijo umetne inteligence. Raziskovali so, ali je pri tem smotrno uporabiti jezikovni model za procesiranje naravnega jezika BERT. Marca letos smo se predstavitve projekta v okviru skupine ACRL Technical Services Interest Group udeležili tudi uredniki Splošnega geslovnika COBISS.SI (SGC) iz IZUM-a.
BERT (Bidirectional Encoder Representations from Transformers/dvosmerne predstavitve kodirnikov iz transformatorjev) je eden najnaprednejših jezikovnih modelov za procesiranje naravnega jezika. Leta 2018 ga je razvil Google in je v nasprotju s predhodniki dvosmeren, torej za učenje uporablja levi in desni kontekst besede. S svojimi novimi algoritmi je močno izboljšal rezultate spletnega iskanja, še posebej pri zahtevnejših iskalnih poizvedbah, ki so pogosto odvisne od konteksta.
Raziskovalci so poskus izvedli pod razmeroma preprostimi pogoji. Uporabili so zbirko Gutenberg, ki vsebuje več kot 70.000 prosto dostopnih digitaliziranih knjig, in s tem razrešili oviro avtorskih pravic. V zbirki so objavljena celotna besedila publikacij; publikacije so procesirane z optičnim prepoznavanjem znakov (OCR), dostopne so v različnih formatih izpisa in vsaka izmed njih v svojih bibliografskih metapodatkih že vsebuje določene predmetne oznake LCSH (Library of Congress Subject Headings) in klasifikacijo LCC (Library of Congress Classification). Knjige so večinoma v angleščini ali romanskih jezikih, tako da se ni bilo treba posvečati težavam, ki bi se pojavile pri sintaktično kompleksnejših jezikih in nelatiničnih pisavah.
Za nabor predmetnih oznak so izbrali geslovnik Kongresne knjižnice (LCSH), ki je najpogosteje uporabljan knjižnični kontrolirani slovar. S klasifikatorji in različnimi orodji za umetno inteligenco so določili osnovne predmetne oznake na horizontalni ravni, nato predmetne oznake na podlagi hierarhičnih odnosov, zatem pa še gesla, ki so jih izbrali na osnovi predvidevanja. Ker je bilo veliko preveč ožjih izrazov (včasih tudi več kot 1.000) in je bila njihova struktura prekompleksna, so se omejili samo na višje stopnje hierarhije. Pri ožjih izrazih pa so predlagali predmetne oznake, ki so se pojavljale tudi pri drugih podobnih knjigah. Kadar je bilo teh oznak preveč, so uporabili metodo najbližnjega soseda. Na koncu so rezultate filtrirali še s klasifikacijskimi podrazredi LCC.
Raziskovalci so se omejili samo na angleške knjige s področja filozofije, psihologije in religije. Ker so ob analizi besedila zajeli tudi pripadajoče bibliografske metapodatke, vključno z oznakami LCSH in klasifikacijo LCC, lahko uspešno ujemanje podatkov v veliki meri pripišemo metapodatkom. Med 3.671 deli, ki so jih strojno analizirali, so izbrali 146 del, za katere so ročno preverili, ali se predlagane predmetne oznake ujemajo z gesli LCSH in pripadajočimi ožjimi, širšimi in sorodnimi izrazi. Okoli 40 % predmetnih oznak se je popolnoma ujemalo in nekaj več kot polovica samo delno. Večina predmetnih oznak je bila torej v celoti ali vsaj delno določena pravilno, samo 4 % jih je bilo določenih napačno in jih ni imelo z vsebino nobene povezave. Podrazrede LCC so določili s 87-odstotno natančnostjo.
Raziskovalci so izpostavili pozitivne in negativne vidike takšnega označevanja. Bili so navdušeni nad predlogi predmetnih oznak, ki jih je ponudil BERT. Bibliografski zapis za delo Life of Luther je imel na primer samo eno predmetno oznako Luther, Martin, 1483–1546, BERT pa je na podlagi besedila predlagal tudi predmetni oznaki Izobraževanje in Reformacija.
Opozorili so na več težav, na primer z besediščem, ki se v klasičnih delih pogosto ne ujema z današnjim jezikom, BERT pa za učenje konteksta uporablja Wikipedijo. Besedišče se namreč skozi čas spreminja, tako se npr. v podobnem kontekstu, v kakršnem se je nekoč uporabljala beseda »melanholija«, danes pogosteje uporablja beseda »depresija«. Raziskovalci se zavedajo številnih slabosti nevrolingvističnega programiranja: kontekstualnost je še nedodelana, dvoumnost (homonimi) ni razrešena, sistem ne prepozna primerov zanikanja, poleg tega so se morali usmeriti samo na močne povezave in manjše zanemariti, da model sploh deluje. Težava je tudi v geslovniku LCSH, ki ima za svoje predmetne oznake prekompleksno sintakso, problematična so predvsem določila. Prisotne so tudi težave s podrazredi pri klasifikaciji LCC.
Vendar kljub temu na vprašanje, ali je lahko BERT v pomoč pri dodeljevanju predmetnih oznak v digitalni zbirki Gutenberg, odgovarjajo pritrdilno. Njihovi rezultati so vendarle pokazali precejšnje ujemanje z dejansko vsebino del. A tudi sami zaključujejo, da avtomatizirano indeksiranje vsebine še ni doseglo take ravni, da bi ga lahko učinkovito uporabljali v knjižničnih informacijskih sistemih in večjih digitalnih zbirkah. Je pa to stvar izvedljive prihodnosti, ki jo vidijo predvsem v preseku razvoja sistemov knjižničnih metapodatkov, temelječih na povezanih podatkih (entitetah in odnosih), procesiranja naravnega jezika (BERT) in vsebinskega modeliranja.
Za naš knjižnični sistem je avtomatizirano indeksiranje vsebine še zelo daleč. Slovenski jezik je kompleksnejši, strojno učenje mora zajemati vse jezikovne posebnosti, kot so skloni in podobno, zato mora biti nujno podprto z jezikovnimi korpusi oz. besediščem slovenskega jezika. Namesto eno- ali večjezikovnega BERT-a bi morali izbrati takšnega, ki je prilagojen za naš jezik (npr. CroSloEngual BERT). Tudi geslovniki še niso tako izpopolnjeni, da bi dali zadovoljive odgovore. Težava je tudi v pomanjkljivi digitalizaciji knjižničnega gradiva in v avtorskih pravicah.

Modeli avtomatiziranega predmetnega označevanja za zdaj niso in verjetno tudi nikdar ne bodo sposobni upoštevati vseh posebnosti, ki jih za zagotavljanje natančnosti iskanja zahtevajo kontrolirani slovarji, kot so SGC, Rameau ali tudi LCSH. Ker pa lahko pričakujemo, da se bo v prihodnosti avtomatizacija tudi na tem področju vse bolj uveljavljala, moramo biti pozorni, da bodo takšna orodja samo pripomoček, ki ga moramo katalogizatorji dodatno preverjati, korigirati in verificirati. Kot dopolnilno orodje pri predmetnem označevanju morda ta metoda ni slaba, vendar brez kritičnega premisleka ni uporabna. Razmišljajoči knjižničar, ki analizira vsebino, je pomemben dejavnik v procesu katalogizacije knjižničnega gradiva, zato ne smemo dopustiti, da bo postala praksa predmetnega označevanja takšna, da knjige sploh nikdar ne bomo odprli.
Prispevek pripravila: Biserka Fortuna
Viri:
-
- Annif (2024). Dostopno na: https://annif.org (20. 9. 2024).
- Chou, C. (2024). An Analysis of BERT (NLP) for Assisted Subject Indexing for Digital Library Collections: A Dialogue Between Library Metadata and Data Science . Spletno predavanje (Zoom), 20. marec 2024.
- Chou, C., & Chu, T. (2022). An Analysis of BERT (NLP) for Assisted Subject Indexing for Project Gutenberg. Cataloging & Classification Quarterly, 60(8), 807-835. Dostopno na: https://doi.org/10.1080/01639374.2022.2138666 (20. 9. 2024).
- Katalog der Deutschen Nationalbibliothek (2024). Dostopno na: https://portal.dnb.de/opac.htm ( 20. 9. 2024)
- Launch of Cataloguing Machine EMa (2024). Dostopno na: https://jahresbericht.dnb.de/Webs/jahresbericht/EN/2022/Hoehepunkte/Erschliessungsmaschine/erschliessungsmaschine_node.html (20. 9. 2024).
- MagicStudio – AI Art Generator (2024). Dostopno na: https://magicstudio.com/ai-art-generator (20. 9. 2024).