
 Fasete so bile med najbolj pričakovanimi in obetavnimi značilnostmi tretje generacije knjižničnih katalogov, saj omogočajo nov način navigacije in omejevanje obsežnih rezultatov iskanja na manjše, bolj obvladljive skupke. Fasete se uporabljajo v vseh fazah iskalnega procesa, zlasti pri splošnih poizvedbah. Poleg tega pa ta tehnika uporabnika kataloga nikoli ne vodi v poizvedbo brez zadetkov, saj so fasete oziroma njihova vsebina vidne le, če so dejansko povezane z virom v rezultatih iskanja.
Fasete so bile med najbolj pričakovanimi in obetavnimi značilnostmi tretje generacije knjižničnih katalogov, saj omogočajo nov način navigacije in omejevanje obsežnih rezultatov iskanja na manjše, bolj obvladljive skupke. Fasete se uporabljajo v vseh fazah iskalnega procesa, zlasti pri splošnih poizvedbah. Poleg tega pa ta tehnika uporabnika kataloga nikoli ne vodi v poizvedbo brez zadetkov, saj so fasete oziroma njihova vsebina vidne le, če so dejansko povezane z virom v rezultatih iskanja.
Fasete so uporabne tudi posredno, zlasti pri evalvaciji virov, saj že vsebina fasete uporabniku ponudi določeno analizo podatkov o značilnostih najdenih virov. In kot kažejo številne raziskave, so uporabniki s fasetami zelo zadovoljni. Pri implementaciji faset je pomembno paziti predvsem na jasno poimenovanje in taksonomijo faset.
Obenem pa se je izkazalo, da je treba posodobiti katalogizacijsko prakso. Z uvedbo te funkcionalnosti so nekateri podatki, ki v preteklih obdobjih niso imeli večje veljave, postali izredno koristni. Tu gre predvsem za nabor podatkov, ki presega opis vira po standardu ISBD. Ko so ti podatki postali vidni, so postale vidne tudi njihove pomanjkljivosti, ki so nastale bodisi zaradi slabo zasnovanih katalogizacijskih pravil (in prakse) bodisi zaradi slabo strukturirane podatkovne sheme (formata) ali pa dejanskih napak.
Fasetna navigacija v COBISS+
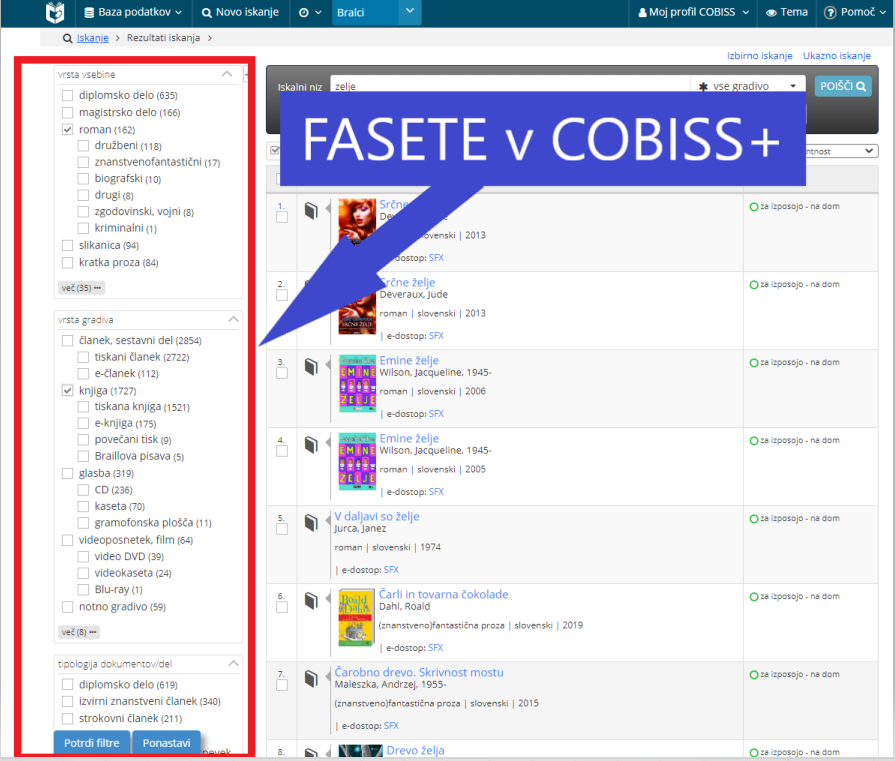
COBISS+ je bil uveden leta 2017. Njegove fasete oz. filtri ponujajo klasifikacijo zapisov po izvedenem iskanju po:
- vrsti vsebine (bibliografski podatki),
- vrsti gradiva (bibliografski podatki),
- jeziku (bibliografski podatki),
- ciljni skupini bralcev (bibliografski podatki),
- avtorju (bibliografski podatki v odnosu do normativne baze podatkov),
- letu izdaje (bibliografski podatki),
- predmetu oz. vsebini (bibliografski podatki)
- tipologiji dokumentov/del (bibliografski podatki, dodano l. 2020) ter
- zalogi v knjižnicah – pri iskanju po več katalogih knjižnic hkrati (podatki iz zaloge) ali
- oddelku – pri iskanju po katalogu knjižnice z oddelki (podatki iz zaloge).
https://www.facebook.com/COBISS.SI/videos/1386189888069373/
Spremljanje kakovosti zapisov dnevne produkcije v letu 2019
Po definiciji, ki jo uporabljamo pri aktivnosti spremljanja kakovosti zapisov dnevne produkcije, je podatek kakovosten, če izpolnjuje več dimenzij kakovosti: je naveden v edinstvenem zapisu (EDIN), ni odvečen (ODVEČ), je semantično točen (SEMTOČ), točno prepisan (TOČPRE), strukturalno popoln (STRUPOP), vsebinsko popoln (VSEBPOP), strukturalno skladen (STRUSKLAD), vsebinsko skladen (VSEBSKLAD), oblikovno dosleden (OBLIDOS), aktualen (AKT) in (lahko) dodatno informativen (DODV) (Badovinac, 2018).[1] Glede na dimenzije kakovosti smo ocenili, da je v vseh podatkovnih elementih, ki se uporabljajo za fasetno omejevanje, možnih 232 napak/priporočil[2].
Podobno kot v letu 2018 rezultati analize spremljanja kakovosti bibliografskih in normativnih zapisov dnevne produkcije v letu 2019 kažejo, da smo tudi v tem letu beležili predvsem pomanjkanje podatkov, katerih vnos v format COMARC/B je v trenutni katalogizacijski praksi le priporočljiv (DODV) (slika 1).[3]

Slika 1: Odstotek slabih podatkov v bibliografskih zapisih glede na dimenzijo kakovosti po posameznih letih 2015 (jun)–2019
Merjenje kakovosti podatkov v fasetah COBISS+
V fasetah se trenutno uporablja že 60 različnih podatkovnih elementov, od tega jih je 15, ki so del normativnega zapisa. V okviru raziskave o možnostih merjenja kakovosti bibliografskih in normativnih podatkov v COBIB.SI smo izvedli manjšo meritev nekaterih dimenzij kakovosti podatkov izbranih podatkovnih elementov, ki se uporabljajo v fasetah in seznamu zadetkov v COBISS+ (Badovinac, 2019). Vzorčenje je temeljilo na osnovnem iskalnem nizu pregleda dnevne produkcije[4] z dodatnimi omejitvami. Upoštevati je treba predvsem to, da vzorci ne zajemajo zapisov, ki so jih kreirali ali redigirali v Narodni in univerzitetni knjižnici (tabela 1).
Za dimenzijo dodane vrednosti (DODV) smo pri bibliografskih zapisih v COBIB.SI, ki so bili kreirani v letu 2018, preverili vnos kode za namembnost (podpolje 100e), ki se uporablja v faseti Ciljna skupina. V okviru vzorčenih zapisov, kjer smo izločili zapise za izvedena dela (dt=d) smo ugotovili, da je podatek manjkal kar pri tretjini zapisov (33,5 %). Če uporabimo isto meritev tudi v za bibliografske zapise, kreirane v letu 2019, je rezultat le za odstotek boljši (32,5 %).
Nato smo preverili tudi zastopanost dveh podatkov v faseti Vrsta vsebine (tabela 1). Koda za literarno vrsto (podpolje 105f) je bila prisotna v 81,1 % zapisih, ki so bili v COBIB.SI kreirani v letu 2018. Iz vzorca smo izključili zapise za sestavne dele (dt=a) in izvedena dela (dt=d) ter zapise z navedeno tipologijo (001t), tako da smo se omejili na zapise za knjižno gradivo (/bma), ki imajo v podpolju 675c vrstilca UDK 821*. Ponovna meritev za zapise, kreirane v letu 2019, pa kaže, da se je delež zapisov s prisotnim podatkom malenkost povečal (83,9 %).
V vzorec o zastopanosti podatka o vrsti vsebine v podpolju 105b smo iz zajema zapisov, kreiranih v letu 2018, izključili zapise za sestavne dele (dt=a) in izvedena dela (dt=d) ter zapise, ki so vsebovali podatke v podpoljih 105f – Koda za literarno vrsto, 001t – Tipologija dokumentov/del in 105g – Koda za biografijo. Podatek o vrsti vsebine (podpolje 105b) je manjkal v dveh tretjinah (58 %) zapisov, ki so bili v COBIB.SI kreirani v letu 2018. Vsi ti zapisi nimajo izpolnjenega niti delno alternativnega podatkovnega elementa – podpolja 001t, kjer se navaja tip dokumenta/dela za potrebe vodenja bibliografij. Podoben rezultat se je pokazal tudi pri meritvi kakovosti zapisov, ki so bili kreirani v letu 2019, kjer je podatek manjkal pri 61,2 % zapisov.
Tabela 1: Mere in vzorčenje glede na posamezno dimenzijo izbranih podatkovnih elementov
| Podatkovni element | Uporaba | Dimenzija | Mera | Vzorčenje v COBIB.SI |
| 100e | faseta | DODV | število bibliografskih zapisov z manjkajočim podatkom glede na število vseh relevantnih bibliografskih zapisov | zajem: dm=2018* not (dt=c or rs=d or rs=p or cr=*old or cr=ctk springer* or cr=uplsi* or cr=knt izum_ or cr=nuk* or re=nuk* or rs=i or dt=d) sken 1–>001a=* ¬ 100e=* |
| 105f | faseta | DODV | število bibliografskih zapisov z manjkajočim podatkom glede na število vseh relevantnih bibliografskih zapisov | zajem: dm=2018*/bma not (dt=c or rs=d or rs=p or cr=*old or cr=ctk springer* or cr=uplsi* or cr=knt izum_ or cr=nuk* or re=nuk* or rs=i or dt=d or dt=a) sken 1–>675c=821* ¬ 001t=* ¬ 105f=*sken 2–>675c=821* ¬ 001t=* |
| 105b | faseta | DODV | število bibliografskih zapisov z manjkajočim podatkom glede na število vseh relevantnih bibliografskih zapisov | zajem: dm=2018*/bma not (dt=c or rs=d or rs=p or cr=*old or cr=ctk springer* or cr=uplsi* or cr=knt izum_ or cr=nuk* or re=nuk* or rs=i or dt=d or dt=a) sken 1–>001a=* & 105b=* ¬ 105f=* ¬ 001t=* ¬ 105g=*sken 2–>001a=* ¬ 105f=* ¬ 001t=* ¬ 105g=* |
![]() Vzorčenje je potekalo 26. 8. 2019 (dm=2018*) in 11. 3. 2020 (dm=2019*). Pomen predpon in pripon ter način iskanja sta opisana v priročniku COBISS3/Katalogizacija.
Vzorčenje je potekalo 26. 8. 2019 (dm=2018*) in 11. 3. 2020 (dm=2019*). Pomen predpon in pripon ter način iskanja sta opisana v priročniku COBISS3/Katalogizacija.
Vnos priporočljivih podatkov
Navkljub temu, da je odziv na priporočila, ki so bila poslana katalogizatorjem, tudi v letu 2019 kar 80‑odstoten, pa na tem mestu katalogizatorje naprošamo, da v zapise dodajo tudi priporočljive, torej neobvezne podatke (npr. podpolja 100e, 1005f in 105b), kadar so ti določljivi. Brez teh podatkov se bibliografski zapis ne bo uvrstil v nekatere fasete, posledično pa pri uporabi fasetnega omejevanja vir ne bo zajet v seznam rezultatov iskanja.
Prispevek pripravila: mag. Branka Badovinac
Reference in opombe:
- Badovinac, B., (2018). Nabor dimenzij za opredelitev kakovosti podatkov v bibliografskih in normativnih zapisih. Organizacija znanja, 23 (1/2), 2–10. Dostopno s spletne strani: http://dx.doi.org/10.3359/oz1812002 [22. 5. 2020]. ↑
- Badovinac, B., (2019). Merjenje kakovosti podatkov v bibliografskih in normativnih zapisih: študija primera izbranih podatkovnih elementov za fasetno omejevanje in izpis seznama zadetkov v COBISS+. Organizacija znanja, 24 (1/2), 1–20. Dostopno s spletne strani: https://doi.org/10.3359/oz1924005 [22. 5. 2020]. ↑
- V letu 2019 smo izvedli 41 zajemov (skupaj 23.609 zapisov). V vzorec je bilo vključenih 2.347 zapisov (povprečno 57,2 % zapisov na zajem), ki jih je kreiralo 372 različnih katalogizatorjev iz 190 različnih ustanov. V letu 2019 smo v 1.063 bibliografskih zapisih s pomanjkljivostjo analizirali 1.917 slabih podatkov na nivoju podatkovnega elementa ali nivoju zapisa kot to določa posamezna dimenzija. Ugotovili smo, da so v letu 2019 najbolj pogosto manjkali priporočljivi podatki (DODV; 43 %) in drugi podatki (STRUPOP; 10 %). Beležili smo tudi težave s točnostjo (SEMTOČ; 12,1 %) in oblikovanjem (OBLIDOS; 9,4 %) podatkov. Sledile so napake vpisa podatkov v napačno (pod)polje ali masko ipd. (STRUSKLAD; 7,2 %), nekaj podatkov je bilo odvečnih (ODVEČ; 8,3 %), drugi so bili pomanjkljivi (VSEBPOP; 2,7 %) ali pa se niso ujemali (VSEBSKLAD; 2,6 %). Zatipkanih podatkov (TOČPRE) je bilo 3,9 % vseh analiziranih slabih podatkov. Dvojnikov zapisov (EDIN) v letu 2019 nismo zasledili. V primerjavi s prejšnjimi leti ni bistvenih razlik; opazimo pa, da se odstotek napačno oblikovanih podatkov (OBLIDOS) in odstotek napak povezane s strukturalno skladnostjo (STRUSKLAD) z leti znižuje (slika 1). ↑
- Zajem zapisov za pregled dnevne produkcije poteka z iskalno zahtevo, ki iz zajema izloči zbirne zapise (dt=c), zapise, označene za brisanje (rs=d), predhodne nepopolne kataložne zapise oziroma CIP-zapise (rs=p), zapise, ki so bili vpisani s konverzijami lokalnih baz (cr=*old), programsko kreirane zapise, ki so vpisani iz baz Springer (cr=ctk springer) in Ebrary (cr=uplsi*) in drugih virov, npr. ISSN baze v bazo ELINKS ipd. (cr=knt izum_), prve vnose zapisov (rs=i) ter zapise, ki so jih kreirali ali redigirali katalogizatorji iz NUK-a (cr=nuk*, re=nuk*). ↑